AbstractNeural plasticity is an important functionality of human brain, in which number of neurons and synapses can shrink or expand in response to stimuli throughout the span of life. We model this dynamic learning process as an L0-norm regularized binary optimization problem, in which each unit of a neural network (e.g., weight, neuron or channel, etc.) is attached with a stochastic binary gate, whose parameters determine the level of activity of a unit in the network. At the beginning, only a small portion of binary gates (therefore the corresponding neurons) are activated, while the remaining neurons are in a hibernation mode. As the learning proceeds, some neurons might be activated or deactivated if doing so can be justified by the cost-benefit tradeoff measured by the L0-norm regularized objective. As the training gets mature, the probability of transition between activation and deactivation will diminish until a final hardening stage. We demonstrate that all of these learning dynamics can be modulated by a single parameter k seamlessly. Our neural plasticity network (NPN) can prune or expand a network depending on the initial capacity of network provided by the user; it also unifies dropout (when k=0), traditional training of DNNs (when k=∞) and interpolates between these two. To the best of our knowledge, this is the first learning framework that unifies network sparsification and network expansion in an end-to-end training pipeline. Extensive experiments on synthetic dataset and multiple image classification benchmarks demonstrate the superior performance of NPN. We show that both network sparsification and network expansion can yield compact models of similar architectures and of similar predictive accuracies that are close to or sometimes even higher than baseline networks. Demo1. The evolutions of decision boundaries of the learned networks on synthetic "Moons" dataset: (left) Network Sparsification, and (right) Network Expansion.
2. Visualization of part of the neurons in conv-layer and fully-connected layer of the LeNet-5-Caffe sparsified / expanded by NPNs. To achieve computational efficiency, only neuron-level (instead of weight-level) sparsification is considered. 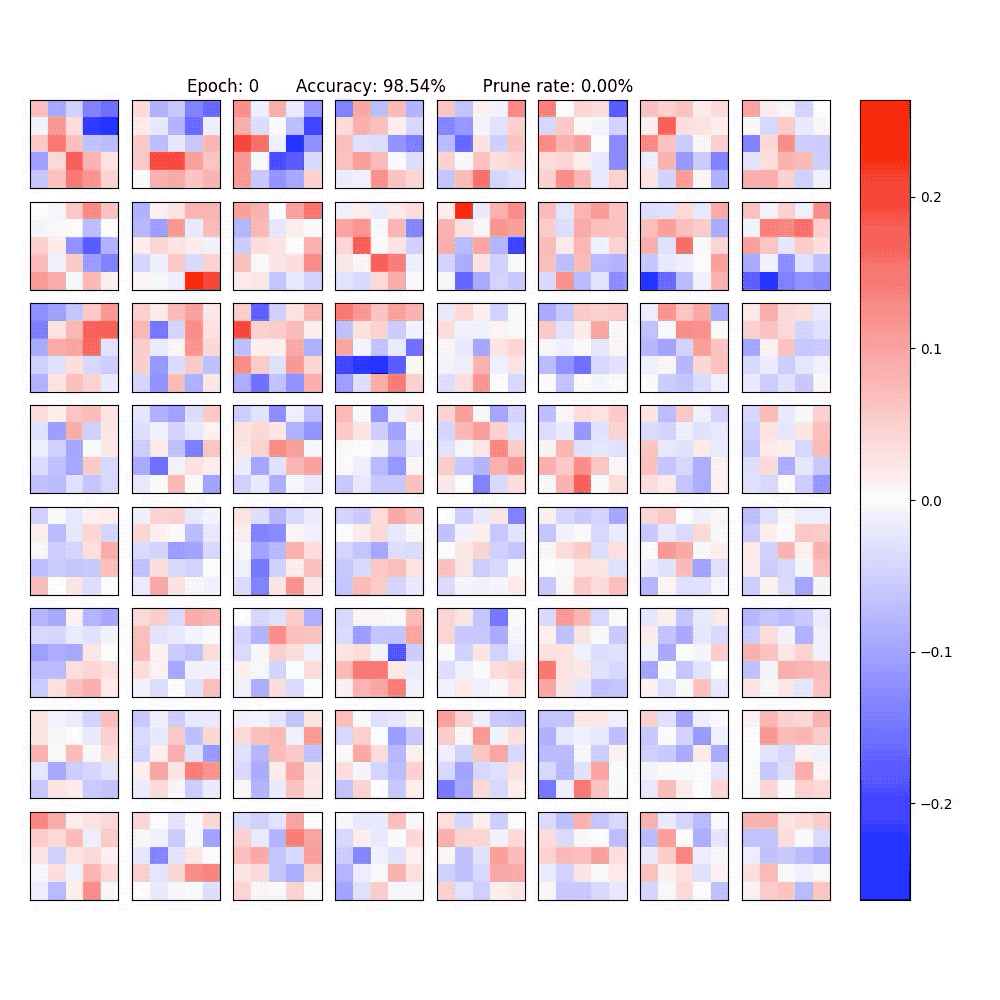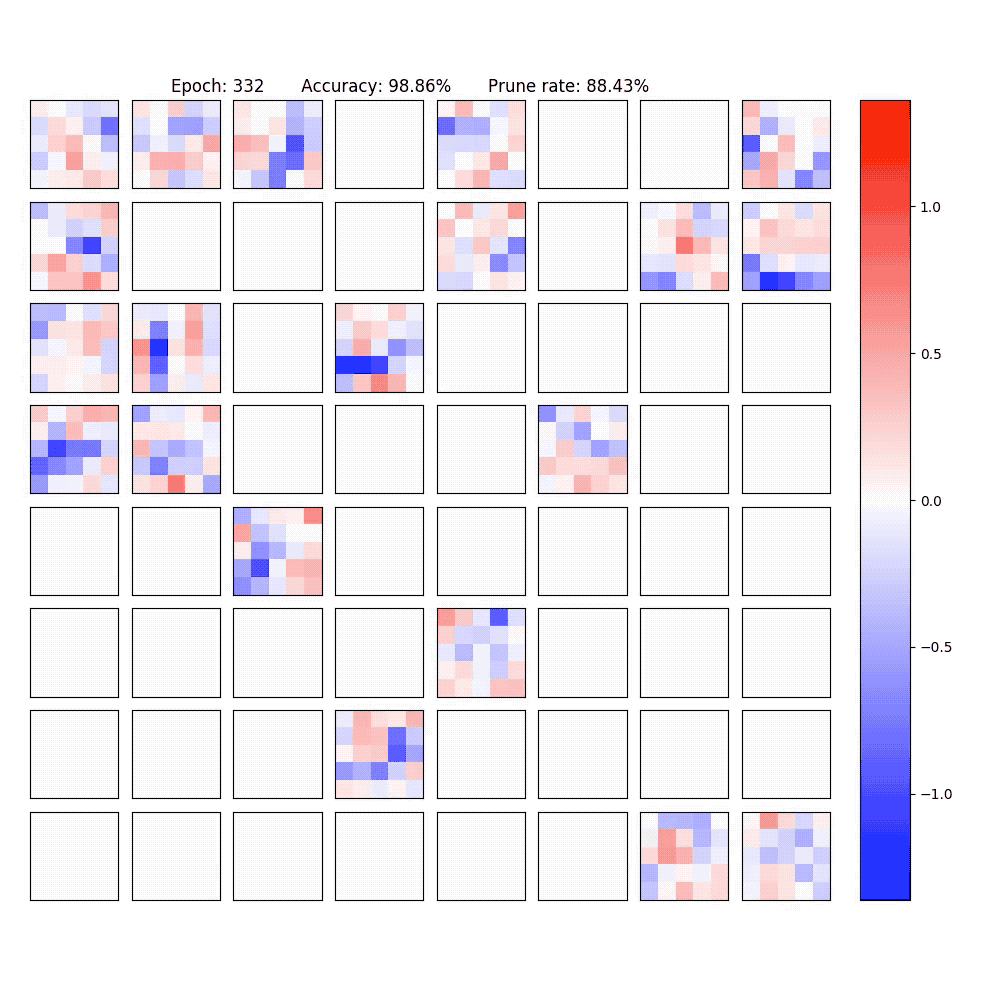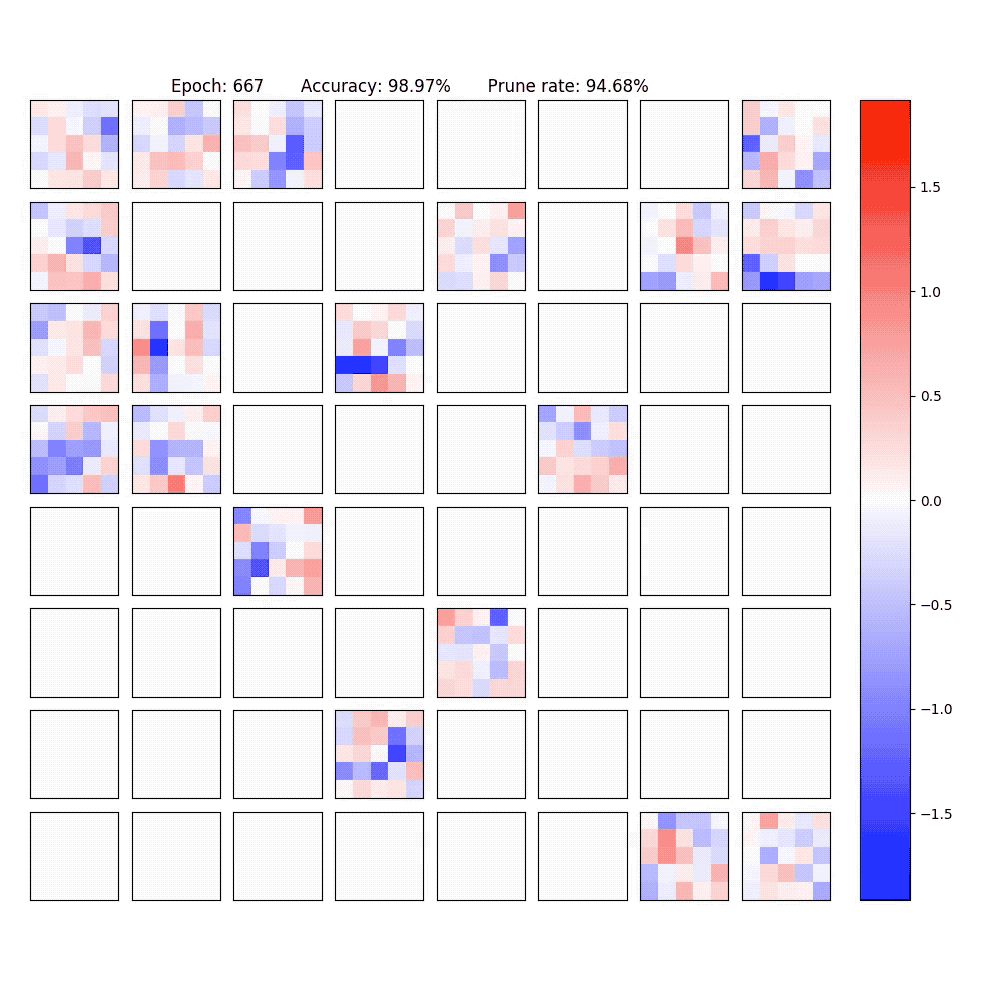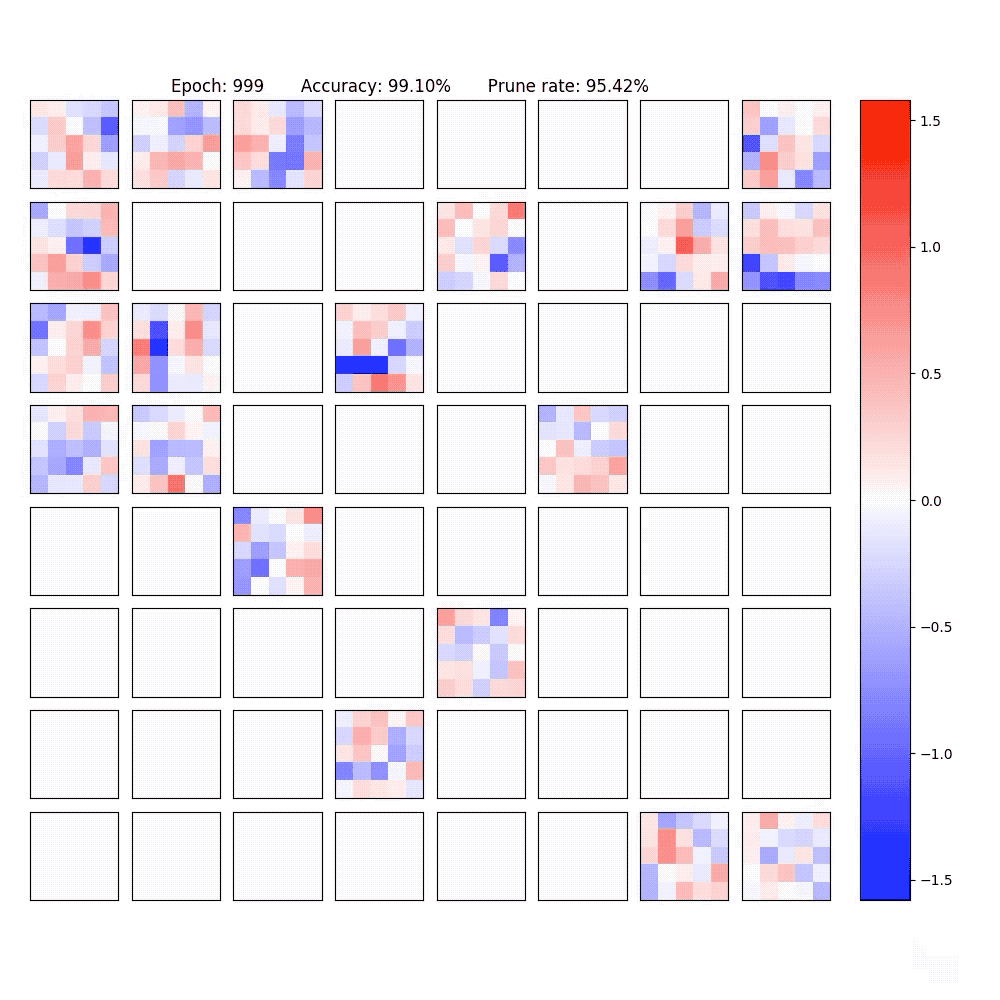
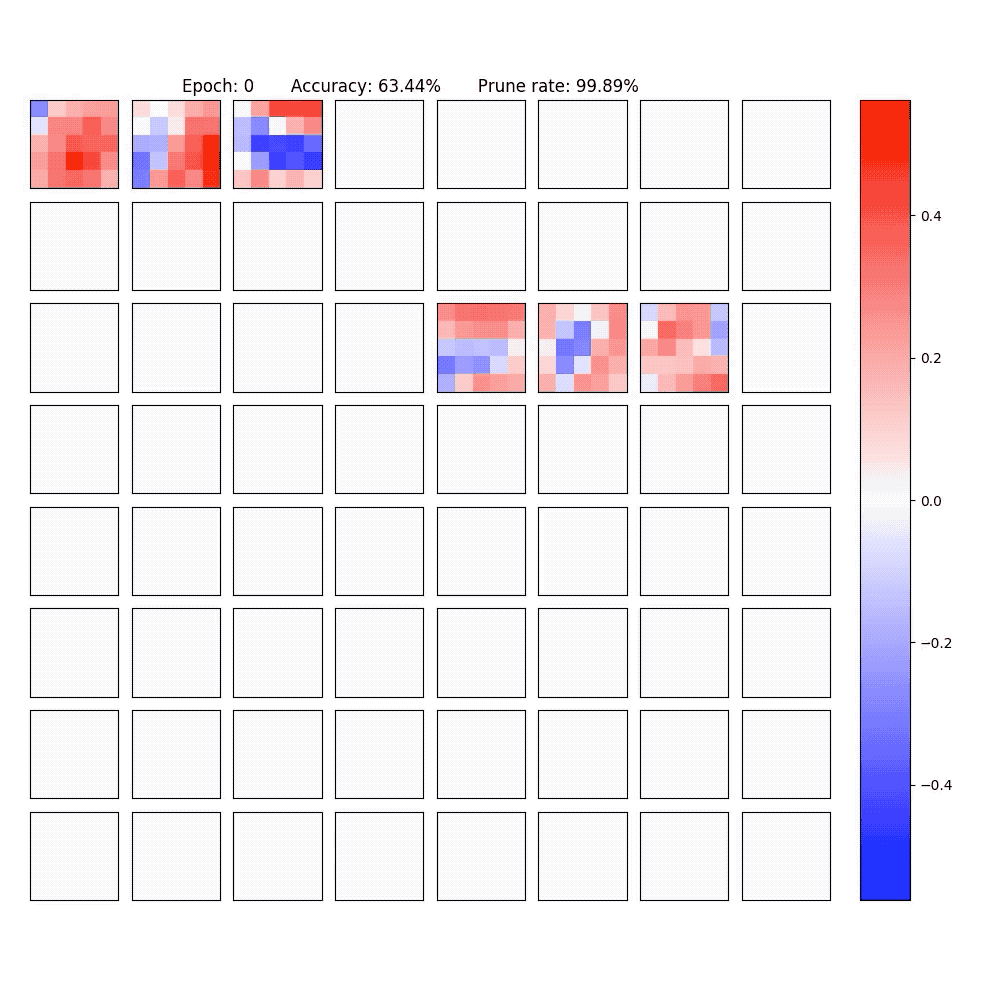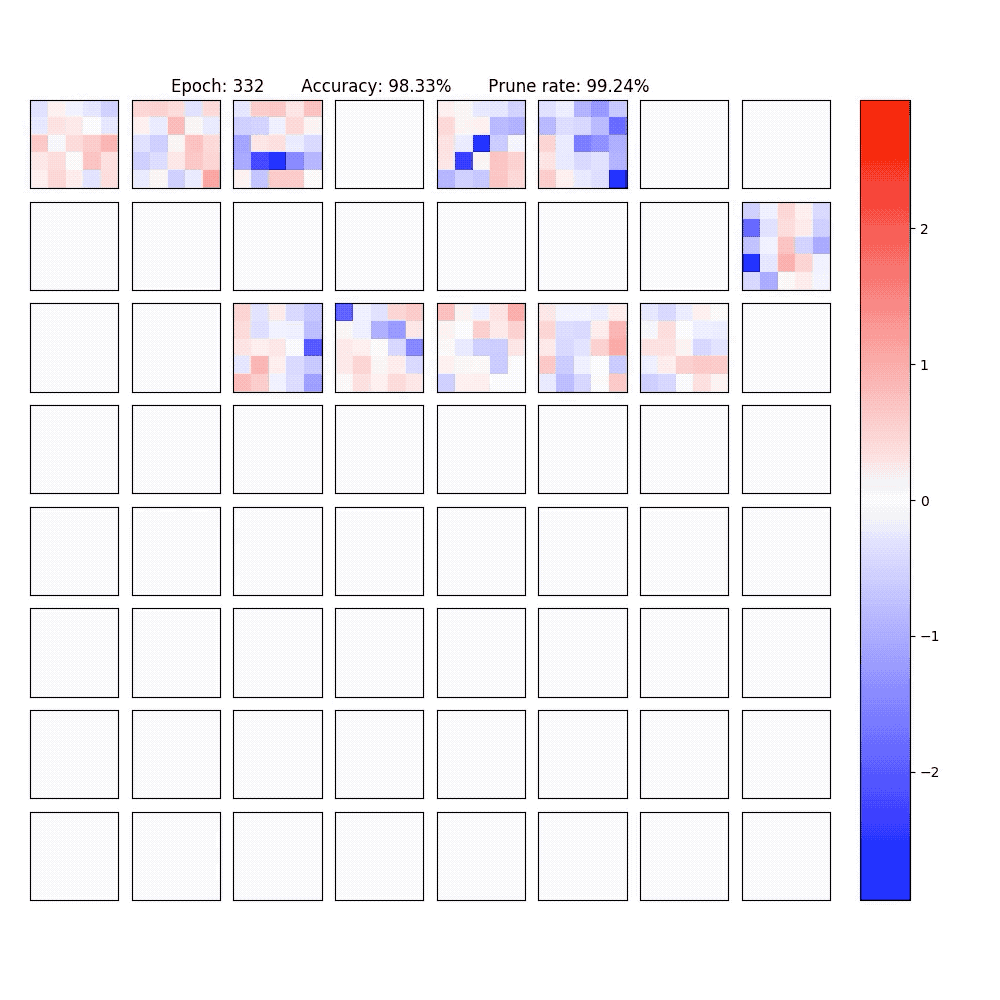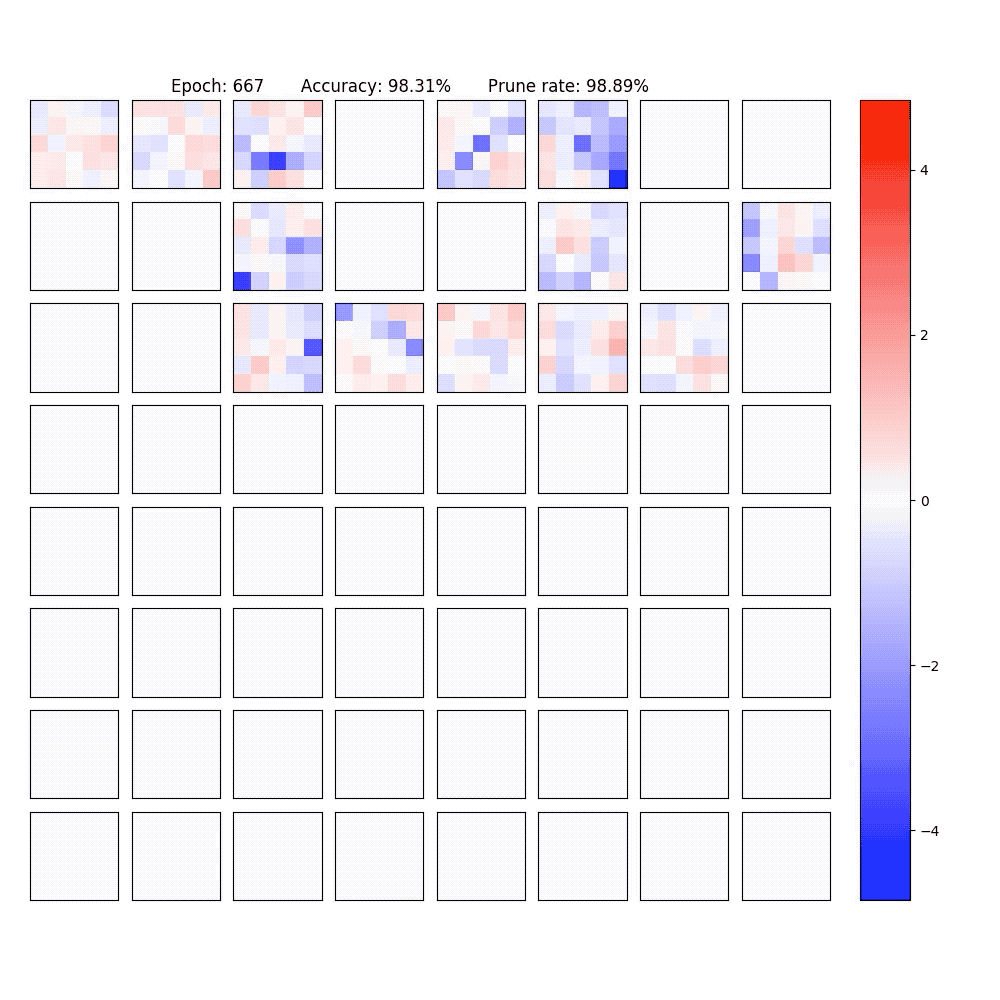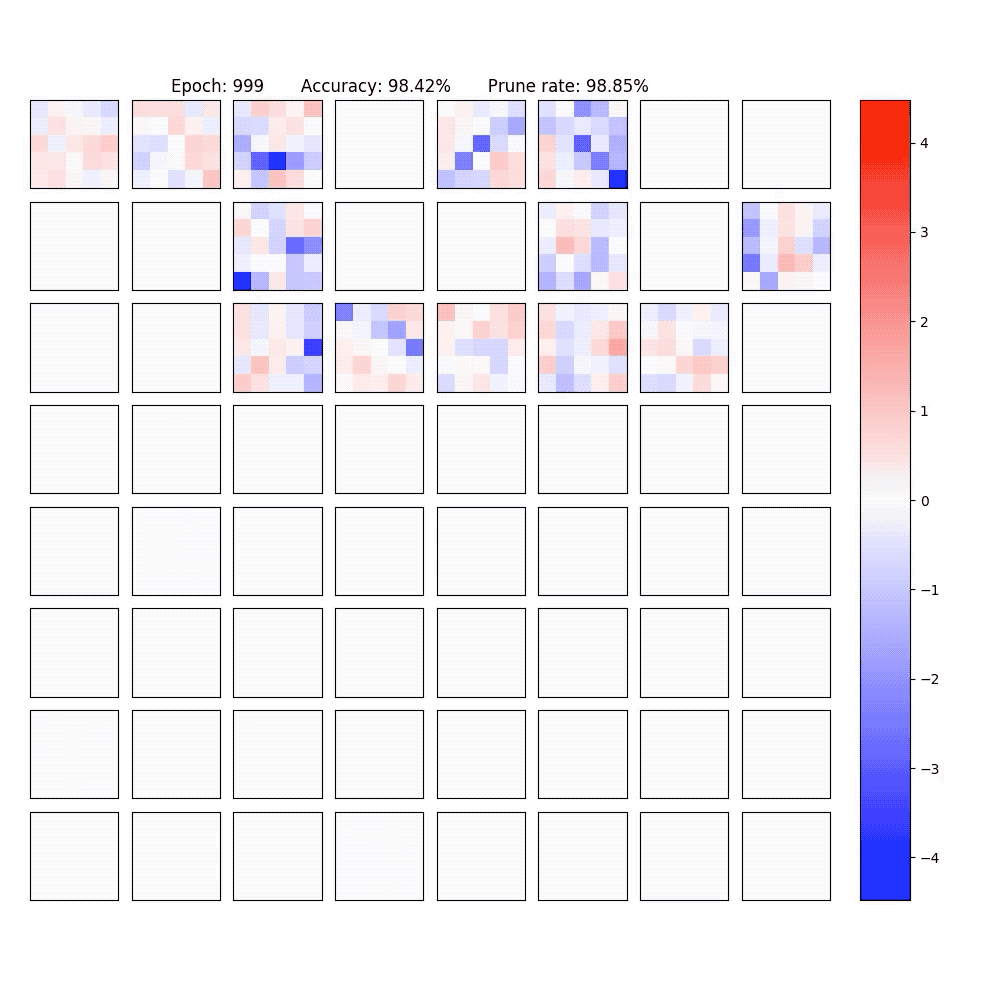
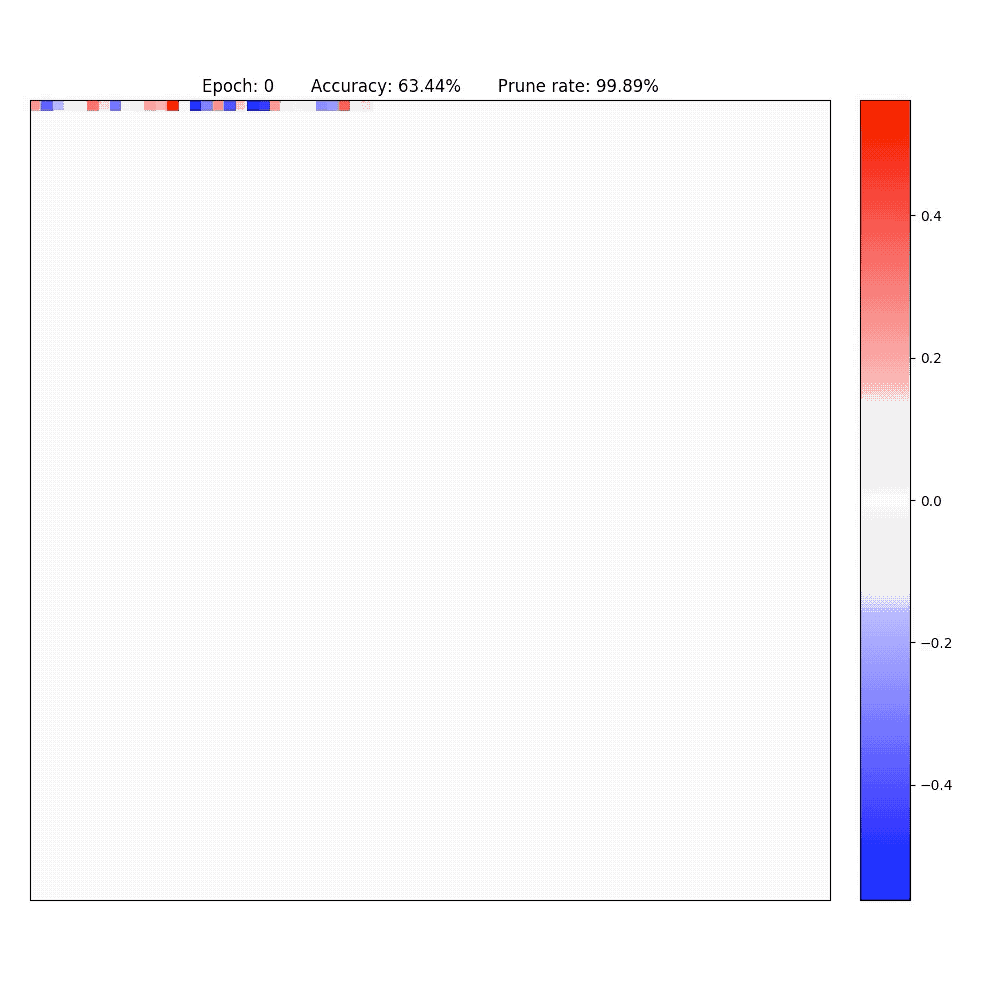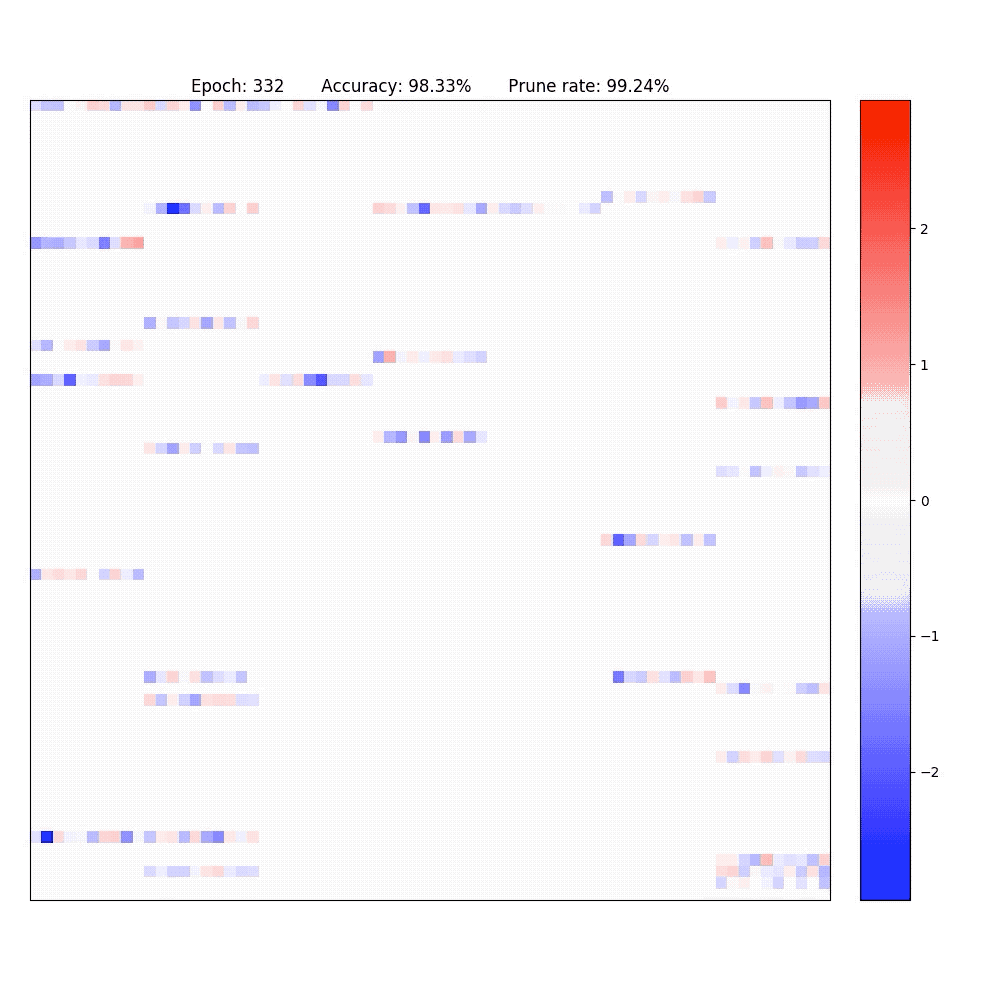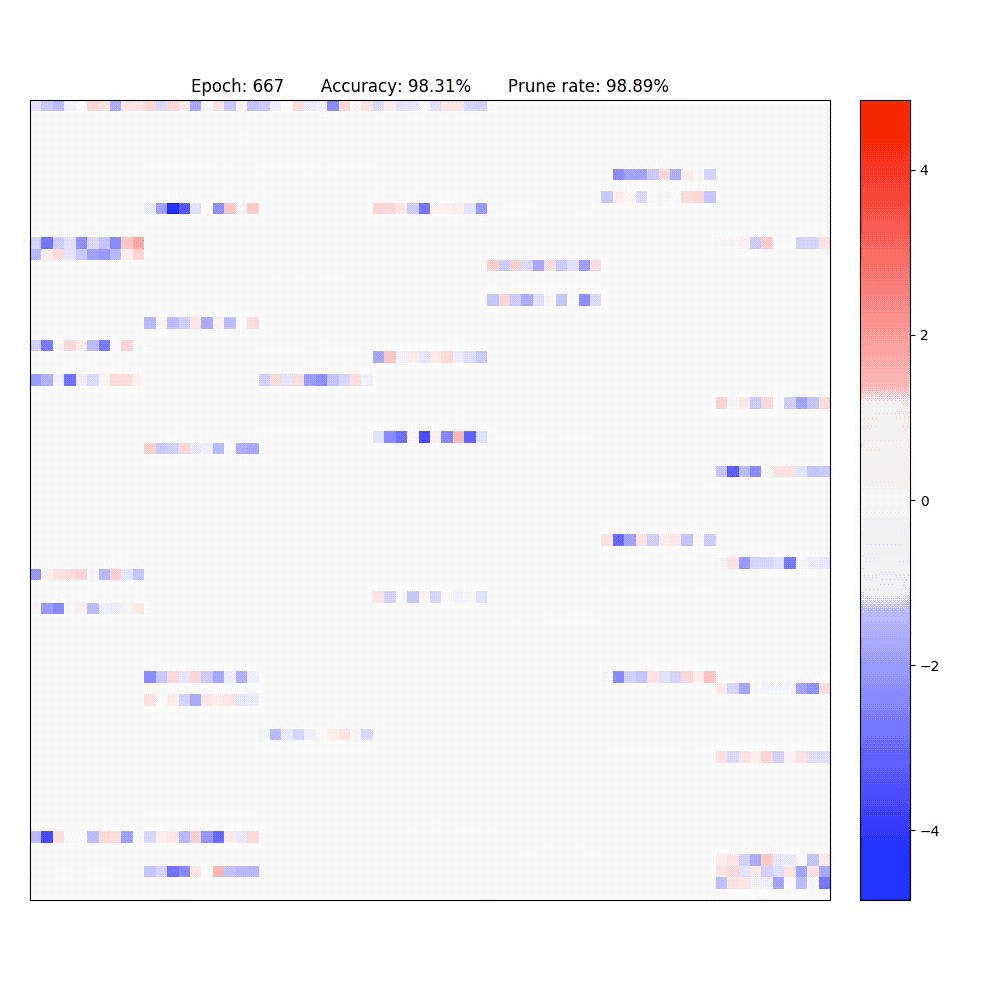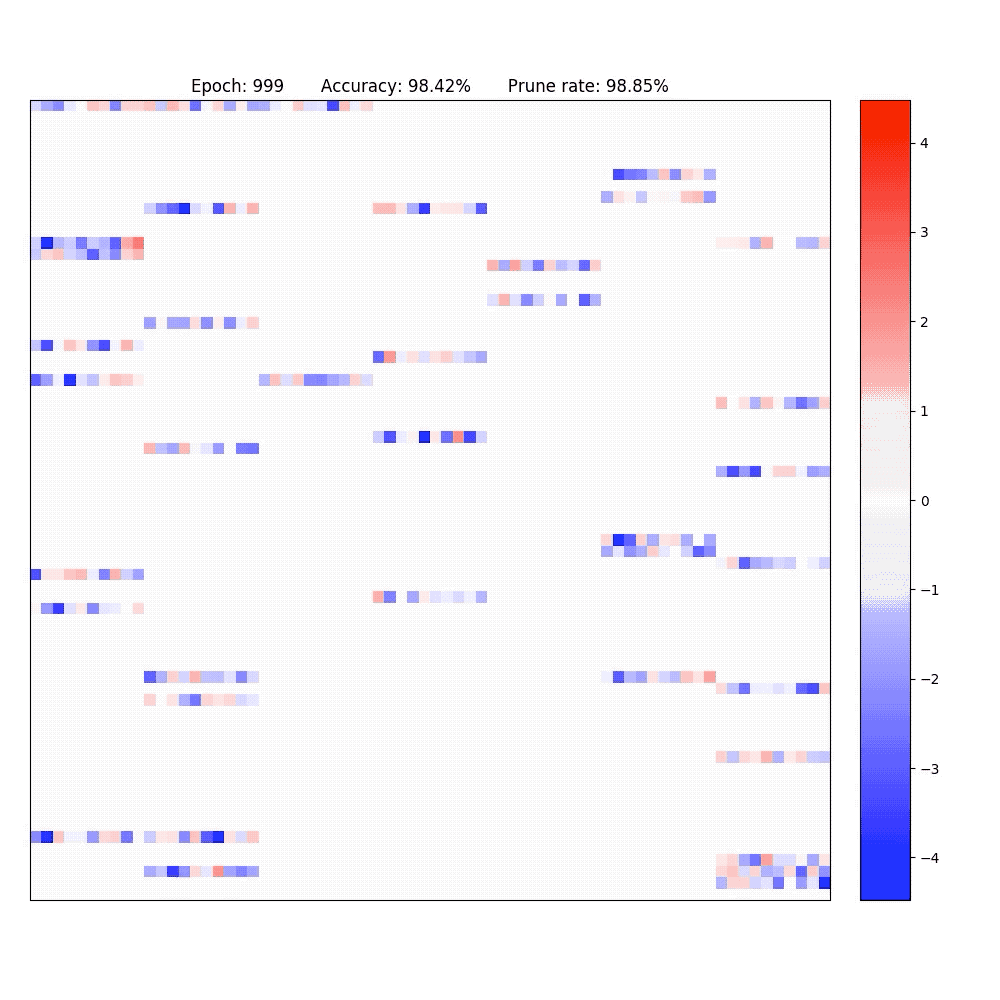
PaperYang Li, Shihao Ji, "Neural Plasticity Networks," International Joint Conference on Neural Networks (IJCNN), July 2021. [arXiv]
|